Bootstrap Azure Subscription for DevOps

This is the first blog post of the blog series about Titan 2.0.
In the vast landscape of data solutions, choosing the right cloud service and data platform is crucial. For our Azure-centric data platform, FFA Titan, we narrowed down our focus to the most fitting technologies. Previously, we relied on Synapse, but Databricks emerged as a strong contender. Although Microsoft Fabric is an interesting option as well, we didn't include it in the comparison. The reason for leaving Fabric out is due to its current limitations in terms of deployment options in Terraform and the missing features that are still on the roadmap.
Our platform, FFA Titan, uses an anchor modeling approach to efficiently capture changes over time. This requirement led us to explore delta.io, which has integrated schema evolution handling. Given that both Synapse and Databricks support Spark, our comparison aimed to uncover which platform better serves FFA Titan 2.0's needs.

Originating from the creators of Apache Spark™, Delta Lake, and MLflow, Databricks was conceived with a focus towards data science and machine learning. In contrast, Synapse evolved from Azure SQL Data Warehouse, positioning itself as a robust data warehousing solution.
Databricks is a multi-cloud solution, contrasting with Synapse's integration within the Azure ecosystem. Databricks facilitates collaborative work through its interactive notebooks that support Python, Scala, or SQL. Synapse, while offering notebook functionality, does not promote the same level of collaboration because you must publish your work first. However, it appeals to a wider audience with its low-code data flow orchestration capabilities. Notebookds in Synapse support Python, Scala, SQL, and C#.
Machine learning capabilities are robust across both platforms. Databricks integrates MLflow natively, whereas Synapse supports both Azure ML and the open-source version of MLflow. When it comes to data governance, Databricks' Unity Catalog provides a streamlined approach for managing data access and sharing datasets. On the other hand, Synapse users must manage access in a storage component without having a native solution for governance tasks.
Our performance tests were designed to evaluate how both engines handle data through various stages, utilizing datasets of different sizes. We used the tpch dummy dataset of databricks and sampled it to a small dataset of 1 GB, kept the medium dataset as is (3 GB) or duplicated it to a large dataset (26 GB). The large dataset is not considered big data, but it was enough to measure performance for different dataset sizes. All data was stored in ADLS gen2 and the following configurations were used:
There is not one configuration of each platform that is similar in size. That is why we took the smallest instances for both platforms (1 and 3) and one size bigger for databricks (2) as this is more similar to the smallest pool in Synapse in terms of RAM and costs. With these three configurations, we processed the dummy datasets as a real-life scenario, applying the following actions per step:
| Step | Action |
| source to bronze | Merge insert to capture raw data |
| bronze to silver | Update schema and data to update datatypes and add some information |
| silver to gold | Create a gold table by joining tables together and adding calculated columns |
| query | Query the gold table and do a count of all rows |
For each step we measured the performance in processing time to see the differences between the operations. In the 'bronze to silver' step, we see a linear correlation with RAM memory, making both 32GB instances twice as fast as the Synapse pool. The biggest difference is realized in the query step, where databricks is about 10x faster in the bigger datasets. When we sum up the processing time of each step, Databricks has better performance with small and medium datasets. For larger datasets Synapse is performing better than the smaller Databricks cluster, but overall the Databricks 32GB cluster wins:
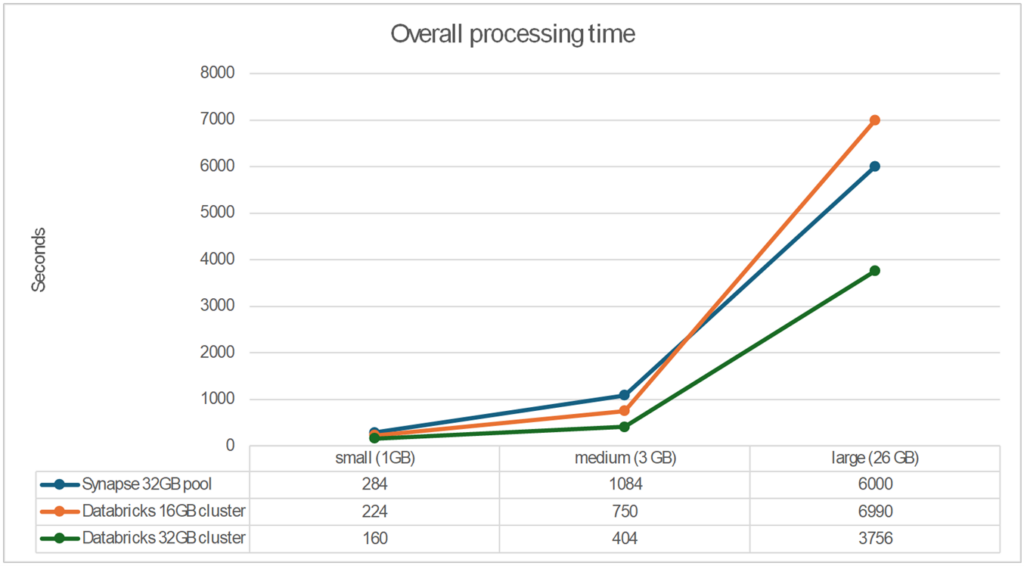
There are several possible explanations for these differences. Databricks developed Delta Lake, so it's inherently optimized for processing Delta format files. More specifically, this means that Databricks efficiently handles metadata operations, caching, and file management within Delta Lake, providing faster query execution times. Additionally, Databricks Runtime includes an optimized execution engine for Spark, offering enhanced performance over standard Apache Spark, which is what Synapse uses. This means that for certain types of operations and data sizes, Databricks can execute queries more efficiently due to its custom optimizations.
To clarify the results, we didn't apply any manual optimization or partitioning, so both services could potentially run much faster. For example, we didn't use the Databricks engine called Photon, designed to accelerate Spark workloads. This new engine is created to better utilize modern hardware architecture, such as vectorized processing and multi-threading, to deliver faster performance on large-scale data processing tasks.
While both platforms were tested for performance, the cost aspect of our decision-making process was also important. Databricks not only outperformed in our benchmark tests but also proved to be more cost-effective for our standard use case. Synapse pools are more expensive than the Databricks clusters with a factor of 5 (compared to the Databricks 16GB cluster) or a factor of 2.5 (compared to the Databricks 32GB cluster).
Although the origin of both services is different, they nowadays have a similar set of advanced data platform capabilities. Both services can be used as a data warehouse, ML platform or for developing a data solution. However, an earlier blog post about FFA Titan 2.0 had some spoiler alerts, and after seeing the results of the comparison it won't be a surprise that Databricks clusters are chosen as processing engine for FFA Titan 2.0.
To summarize, the difference in performance, cost benefits, and the slightly more convenient interactive notebooks convinced us to use Databricks. Nonetheless, recognizing Synapse's strengths in low-code orchestrations tasks, we decided to use Databricks clusters within Azure Data Factory, thus using the best of both worlds.
Optimizing cluster sizes, using autoscaling, and selecting appropriate performance levels are key strategies for cost reduction in both Databricks and Synapse. We'll dive more into this topic in an upcoming blog.
Databricks promotes real-time collaboration in its notebooks, while Synapse requires publishing work for sharing, making Databricks more conducive to interactive team analysis.
Databricks supports real-time data processing through its structured streaming feature, while Synapse offers stream analytics capabilities, enabling both platforms to handle real-time data workflows.